
使用 Turi Create 製作圖案辨識的 App - Core ML and Vision
使用 Turi Create 製作圖案辨識的 App - Core ML and Vision
Turi Create是一個拿來做 machine learning model 的 Python 模組,在 WWDC18 上,有多個 Session 直接在現場使用這個模組直接 Demo。他可以讓 iOS 開發者在使用 Core ML 模組時,更專注在 APIs…
使用 Turi Create 製作圖案辨識的 App - Core ML and Vision

“A person’s hand holding a camera lens over a mountain lake” by Paul Skorupskas on Unsplash
Turi Create是一個拿來做 machine learning model 的 Python 模組,在 WWDC18 上,有多個 Session 直接在現場使用這個模組直接 Demo。他可以讓 iOS 開發者在使用 Core ML 模組時,更專注在 APIs 的行為上。除些之外,你如果有些初步的想法,你不用去找一個 ML 專家或是把自己變成 ML 專家,也能做出一個初步的 ML Model,讓這個 model 先做 prototype 再發揚光大。
在 WWDC18 Session 712 中,整個 session 都在介紹 Turi Create,如果對那個 Session 有興趣,你可以看下面這一篇 Medium。
WWDC18, Session-712 Turi Create 重點整理 -製作ML model 不再是一個困難的事
_Turi Create 是什麼?_medium.com
讓我們開始 Demo Turi Create 裡面會用到的 API,以及他怎麼實作吧。我們要實作的是判斷這張圖裡面是不是金城武。範例影片放在這個 Youtube 上,除了判斷是不是金城武以外,還加上了信心指數。
信心指數的意思,你的 model 對這個結果有多少的信心,這個數字會在 0~ 1.0 之間。如果他判斷這張圖不是金城武,然後信心指數是 0.97。就表示這個 data 對這個 model來說,「不是金城武」這結果有 0.97 的信心指數。
要做 image classification 前,你需要有 image data,然後針對該分類建立資料夾,並把對應的圖片放到資料夾內。當然資料是愈多愈好,但至少該放多少呢?蘋果的投影片中有提到,建議至少放個 40 張當做 data。
如下圖所示,我在網路上搜尋了 40 張金城武的照片,然後放進 kaneshiro 這個資料夾。不過比較困難的地方,是「非金城武」這邊的 data 應該放什麼呢? 就邏輯來說,就是放所有非金城武的照片,但這些照片到底該放哪些呢? 因為是範例,所以我這裡就先放數十張非金城武的人像照當做 demo ,真正在做這種專案的時候,還是建議詢問資料科學領域的人,你想處理的資料該怎麼訓練模型。
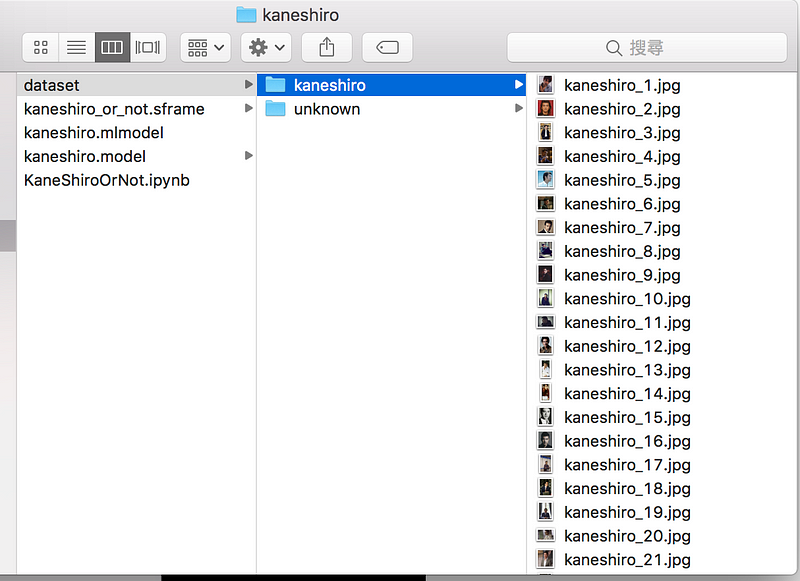
在 dataset 內放 kaneshiro的照片,unknown 則放不是目標的照片
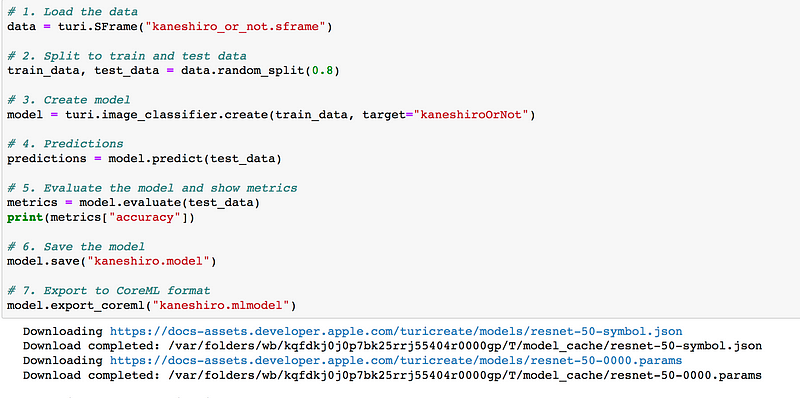
當你的資料放好了,你就可以用下面這些程式碼進行 model 的訓練和 Core ML 的輸出。程式碼的數量相當的低,這邊只用了 12 行而已 (註解不算)。你可以在 (Ref-1) 上直接下載 Jupyter Notebook 的檔案
Turi Create 在讀取檔案的時候非常聰明,如果他讀的案是他不支援的,他會吐出 error message,但程式會繼續執行。下圖示範了這個結果,.DS_Store 是 mac 系統裡面存放空間資料用途,這是給 Mac OS 的 finder 程式使用的。
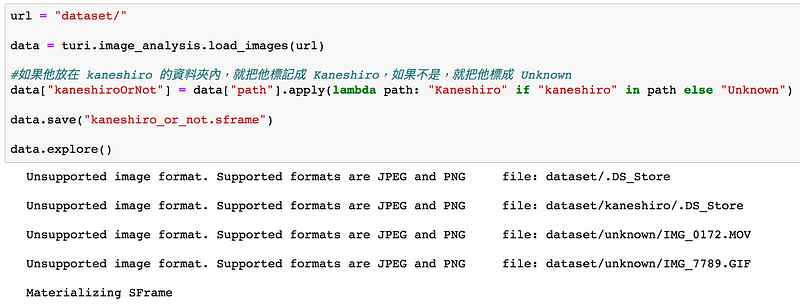
讀到不是JPEG和PNG 以外的檔案會跳過
如果你的 Jupyter Notebook 是第一次跑,程序會連到 Apple 的 model 網站去下載相關資料。
Message 的 downloading 就是連到Apple網站去下載模型資料
下面就是模型訓練時, Turi Create 會吐出來的資訊
Analyzing and extracting image features.
+——————+————–+——————+
| Images Processed | Elapsed Time | Percent Complete |
+——————+————–+——————+
| 64 | 3.16s | 50% |
| 74 | 11.34s | 100% |
+——————+————–+——————+
Logistic regression:
-——————————————————-
Number of examples : 74
Number of classes : 2
Number of feature columns : 1
Number of unpacked features : 2048
Number of coefficients : 2049
Starting L-BFGS
-——————————————————-
+———–+———-+———–+————–+——————-+
| Iteration | Passes | Step size | Elapsed Time | Training Accuracy |
+———–+———-+———–+————–+——————-
| 0 | 1 | NaN | 0.017910 | 0.540541 |
| 1 | 7 | 0.000083 | 0.125282 | 0.540541 |
| 2 | 10 | 5.000000 | 0.181402 | 0.918919 |
| 3 | 11 | 5.000000 | 0.207410 | 0.945946 |
| 4 | 12 | 5.000000 | 0.242203 | 0.459459 |
| 5 | 14 | 1.000000 | 0.280374 | 0.864865 |
| 10 | 20 | 1.000000 | 0.409511 | 1.000000 |
+———–+———-+———–+————–+——————-+
Completed (Iteration limit reached).
This model may not be optimal. To improve it, consider increasing `max_iterations`.
Analyzing and extracting image features.
+——————+————–+——————+
| Images Processed | Elapsed Time | Percent Complete |
+——————+————–+——————+
| 13 | 2.53s | 100% |
+——————+————–+——————+
1.0
我個人覺得這個模組很棒的地方,是他會提示你這個模型是不是需要再修正。像上面的 message 中可以看到一行: This model may not be optimal. To improve it, consider increasing `max_iterations`. 這是因為我 max_iterations 只給預設值,結果他跑出來後覺得這個模型準確率太低,並直接建議你調高 max_iterations。
跑完後你就可以拿到 mlmodel 這個檔案,而且你還可以看到 model 細項。以本文為例,你可以看到他有說明這個是 mlmodel 是用於 image clasifier,而且是從 Resnet-50 訓練出來的, Turi Create 版本是 5.0 beta 3。
底下則是 input 和 output 訊息,你要輸入的是彩色 224 x 224 的圖片。然後他輸出有兩個,如果是 kaneshiroOrNot,則是這個 model 判出來的結果。因為當初我們只設定兩個 label,一個是 Kaneshiro,另一個是 Unknown。所以這一項一定是這兩個其一。
另一個輸出是 kaneshiroOrNotProbability 他是個 dictionary,key 是每個 label,value 是該 label 的信心指數,雖然這個範例只有兩個 label ,但實際上你能訓練出能辨試多種水果的 model,這時候你可能會想知道每個 label 的信心指數,去看有沒有可能有近似的結果,再去做處理。

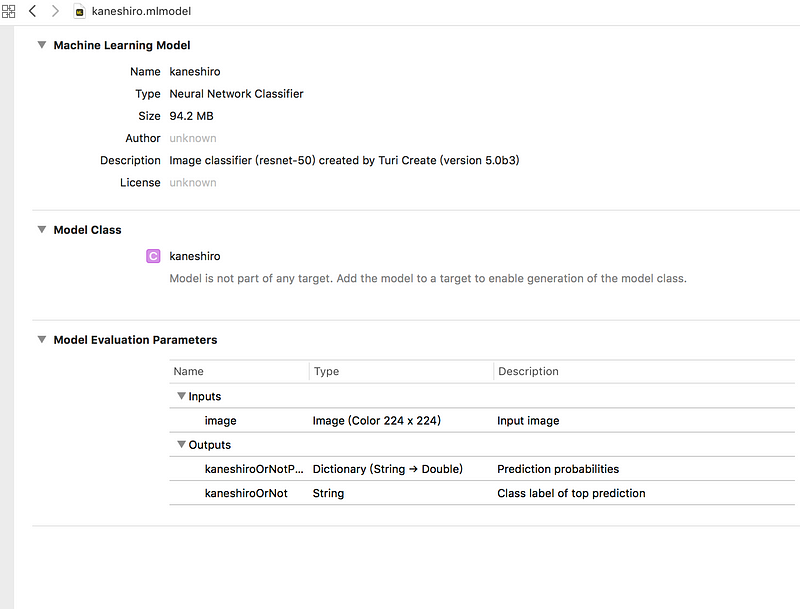
mlmodel 的細項,這包含用什麼模型做訓練,以及輸入的格式,輸出的格式。以本文為,輸出有兩項kaneshiroOrNot 輸出一個string,是指他判斷出來的 label。另一個則是每一項的信心值數字。
接下來,我們開始寫圖像辨識的專案吧。因為這個專案極有可能用到照相機和相簿功能,請記得在 info.plist 裡面做 Privacy 請求。

請記得在 info.plist內做這兩個功能要求
在這裡,我先使用 App Coda 的方法 (Ref-2)讓 ML Model 去讀取 UIImage 檔案。我也試用過 Vision 模組的 VNRequest,但辨識的結果差很多,而且該檔案和模組都是直接從 Apple 上下載下來的。我想,可能還有些參數我應該要調整才能讓辨識率提高。目前 App Coda 的這個方法,辨識率還不錯,就先用這種方式。
在 UIImage 裡面 extension buffer 這個 method。讓原來的 image data 專換成 VCPixelBuffer 格式, Core ML 模組才能辨識。
UIImage extension 後,讓 image 直接轉換成 CVPixelBuffer
接下來就是辨識的核心 method。因為我們的 MLModel 是基於 Resnet 所訓練出來的,所以他吃的是 224 x 224 的 image,這個資訊你可以在 MLModel file detail 看到。
接下來,只要在取得 image 物件後,去呼叫 judgeKaneshiro(:),就完成了。舉例來說,像是鏡頭取得 image 後。
func imagePickerController(_ picker: UIImagePickerController, didFinishPickingMediaWithInfo info: [String : Any])
實際跑一遍,你會發現,這個範例並沒有那麼準,比如說,有幾張金城武的照片,因為髮型或者背景不一樣,他就認為這不是金城武。然後,我也試著把古天樂放進去判斷看看,結果他認為這個是金城武。這樣的問題並沒有辦法在這裡用程式碼解決,因為這是 mlmodel 判斷的結果。要處理的話,要從訓練 model 那邊開始下手。建議你可以試著換換 model,或是調整 dataset,或是調一下 max_iterations 參數試試看。

雖然大部分的照片都可以分得出來

但是仍然有判錯的情況,古天樂被當成金城武了,而且髮型改變比較大,就認不出來了
整個專案都放在下面這個 GitHub ,你可以在 Project_KaneshiroOrNot 中找到 XCode 的檔案。Turi Create 的程式碼則可以在 Jupyter Notebook 的 folder 中找到。
Ref-1: GitHub位址
MoonAndEye/TuriCreateDemo
_GitHub is where people build software. More than 28 million people use GitHub to discover, fork, and contribute to over…_github.com
Ref-2: App Coda 的範例, 分辨照片是湯或是飯
Creating a Custom Core ML Model Using Python and Turi Create
_In the past few years, the use of machine learning approaches to solve problems and perform complex tasks have been…_www.appcoda.com
By Marvin Lin on August 20, 2018.