
資料密集型應用系統設計-第六章筆記
這世界上沒有銀色子彈 https://g.co/kgs/G7QbDr
資料密集型應用系統設計-第六章筆記
這世界上沒有銀色子彈 https://g.co/kgs/G7QbDr
為什麼需要分區?
- 可擴充性增加
- 只要業務量增加,最終單一伺服器總會遇到上限,在需要擴增的狀況下,選擇適當的分區策略,對未來的業務會有更大的助益。
- 增加效率
- 當分區策略做的好,在查找的效率會提高。
- 增加安全性
- 在特定狀況,可以將資料分成敏感性和非敏感性,分開存放。並在前面放上 security control,在不同
- 增加操作的彈性
- 因為不只一個儲存資料的地方,就可以有更多可優化的方法。像是 management, monitoring, backup and restore
- 讓資料的本質更貼近儲存的型別
- 分區是可以依照資料類型而分的。對於大的 binary data 的資料,放進對 blob storage 有優化的區,比放在 document database 更好。
- 增加可靠性
- 分區可以避免 single point of failure 等情形。
分區的策略
水平分區 Horizontal partitioning
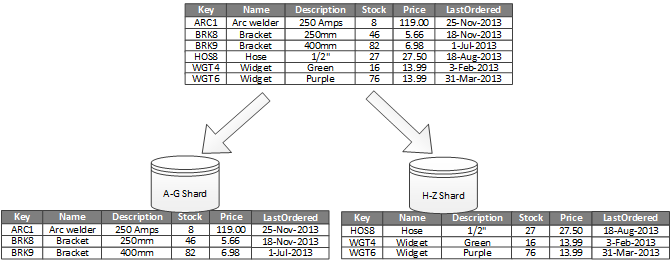
每個分區分掉一部分的資料,這個策略中比較好的策略是讓每個分區對系統的負擔是差不多。每個分區擁有相同的 schema。每個分區也被稱之為 shard 。
水平分區的舉例,會將分區依照 key 的字母順序排列。這個策略最重要的是決定 sharding key 的範圍,因為策略一但執行並上線之後,就很難再度調整。
但這並不表示應該讓每個分區所擁有的「數量」一樣,在書本上的例子,是用百科全書為例。但是百科全書是個出版品,如果出版社想讓每本書的厚度相近,就會設計的讓頁數相近,所以排列的方法是讓字母順序的分區,能讓分區後的詞類和解釋的數量相近。
但是就資料庫而言,並不單純是「擁有的資料」,也有可能依照現實情境設計。可以設計成某個 shards 擁有的資料很大,但每個 item 的讀/寫頻率很低。而其他分區擁有的資料很小,但是讀/寫頻率很高。
要注意的點:
要確保每一個 shard 不會超過機器的物理上限。
需要避免製造出會影響效能或可靠近的「熱區」,舉例來說,如果設計讓顧客的首字字母當做分區的 Key 分類,就會造成某些分佈不均,因為人類的語言上會有常用習慣。可以替代的方案,就是先經過 hash 函數,再分散放入分區中。
垂直分區 Vertical partitioning
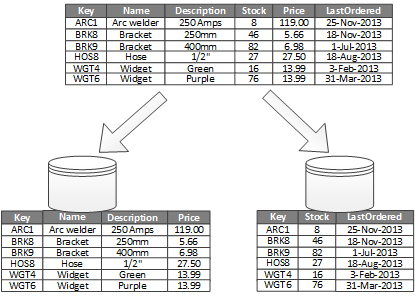
每個分區都擁是原始資料的子集合。舉例來說,將欄位分成常用和不常用的部分,常用的欄位放在某一分區,不常用的放另一分區。
縱向分區最常使用的場景,就是減少 I/O 和降低高頻率拉取資料的成本。
以上 Fig2 為例,一個分區存放高頻率被存取的資料,包含產品名稱,描述,價格。另一個分區存放的資料,是倉庫中的庫存和上次訂購的時間。在這個例子中,這個系統常常會因為 App 需要顯示,而要去 query 產品名稱、描述、價格。
而庫存數量和上次購買日期會放在一區,是因為這兩個 item 常常一起在同一個區段顯示。
其他優點
不常變更的項目,和常常變更的項目會切開。在這個例子中,產品名稱,描述,價格是不常變動項目。而庫存數目和上次購買日期是常常變動的項目。而不常變動項目的區間,是很容易被選到放在記憶體中的快取。
敏感型資料可以分區存放,並加上 additional security controls。
垂直分區可以減少所需的併發型 access。以上面的例子來說,如果當 client 真的發生訂購行為,會更動庫存和上次購買時間。垂直分區的策略,不會讓整條 row 鎖住。而這個策略,也因為只要特定欄位,在 MSSql 以 Page 為單位時,每個 Page 可包含的 row 數量會比使用水平分區策略的多。
功能分區 Functional partitioning (Microsoft 的文章)
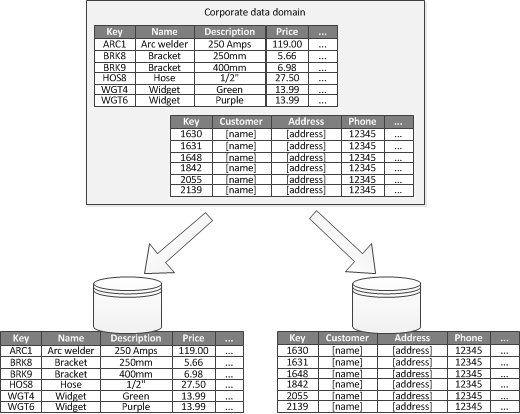
功能分區。將資料依照「如何被使用」來分,舉例來說,如果架設電商系統的分區,會將產品庫存資料放在一個分區,而發票/收據資料,放在另一個分區。
如果商業邏輯的邊界是很明顯的,那依照功能切分是可以提升效率的。常用的場景是,將 read-write data 和 read-only data 放在不同區分。在 Fig 3 中的場景,是將庫存資料和客戶資料放在不同區分。
Key or hashed base sharding
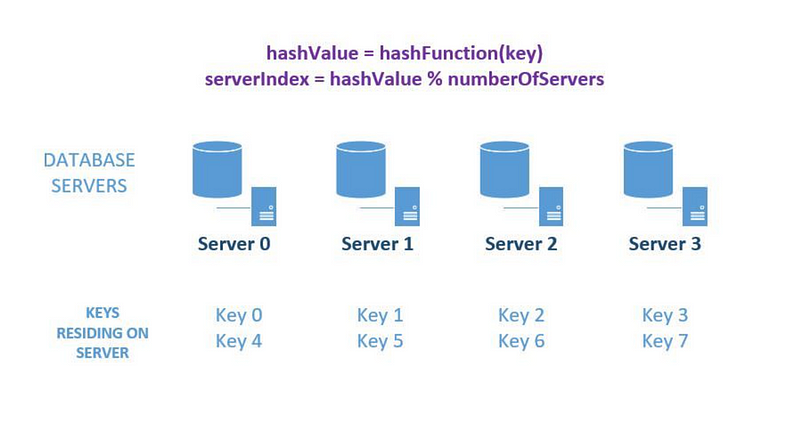
假設你有四台 database servers,每個 request 都有 application id。只要使用 hash 和 mod ,就能將資料分散到四台機器上。
這個方法的主要缺點是, elastic load balancing (dynamically adding/removing database servers) 會非常困難,而且成本很高。
假設,你想要多加六台機器,就必需進行 remapp 和 migration。除此之外,你還要調整你的 hash function,從 mod 4 變成 mod 10。
現在,是有不停機的轉換的方式,如 Consistant Hashing,參考資料如下。
https://www.acodersjourney.com/system-design-interview-consistent-hashing/
Directory based sharding
Directory based shard 分區會在分區前面加上 lookup service。lookup service 知道現在的分區 scheme,並在系統中留存一份 map 紀錄。
client 端會先去問 lookup service,去找出 entity 是被放在哪個 shard,然後才會進行查找的動作。
優點
可以解決 elastic scaling 問題,而且是在不使用 consistent hashing 的前提。先假設前面的擴張情況,四個 database service 配上 hashed based 區分策略。現在要加上六個 database servers 而且不想停機。
步驟如下
1> lookup service 仍然使用 mod 4 hash function
2> 先區分出,如果在 mod 10 的狀況下,資料該怎麼區分
3> 寫一段 script 把所有的資料 copy 到新的六台 shards 上,注意,此時並不會刪掉原來四台上的資料。
4> 當 copy 完成,換掉 lookup service 上的 hash function,從 mod 4 換成 mod 10。
5> 將 4 台舊資料上的資料清掉 (稱之為 purge 或 clean up)。
在實務上要注意的地方
migration 時,使用者還是有可能在更新資料。可能的解法,將系統轉為 read-only mode。或是先將這個時間的資料,放到另一個 service 上,等到 migration 結束再移回來。
copy 和 clean up 對效能會有很大影響。可能解法就是 cloning and elastic load balancing,但這兩個方法的成本都很高
參考文章
分區的文章
https://www.acodersjourney.com/database-sharding/
Consistent Hashing
https://www.acodersjourney.com/system-design-interview-consistent-hashing/
Microsoft 對工作負載和熱點降溫
https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning
By Marvin Lin on November 2, 2021.