
Designing Data-Intensive Applications - Chapter 6 Notes
There is no silver bullet: https://g.co/kgs/G7QbDr
Designing Data-Intensive Applications - Chapter 6 Notes
There is no silver bullet https://g.co/kgs/G7QbDr
Why do we need partitioning?
- Increased scalability
- As business volume increases, a single server will eventually hit its limit. Choosing an appropriate partitioning strategy can greatly benefit future business needs.
- Improved efficiency
- A well-designed partitioning strategy can enhance lookup efficiency.
- Enhanced security
- In certain situations, data can be divided into sensitive and non-sensitive categories and stored separately with security controls in place.
- Greater operational flexibility
- Multiple storage locations allow for more optimization methods, such as management, monitoring, backup, and restore.
- Data type-specific storage
- Partitioning can be based on data type. For large binary data, storing in an optimized blob storage area is better than in a document database.
- Increased reliability
- Partitioning can prevent single points of failure.
Partitioning Strategies
Horizontal Partitioning
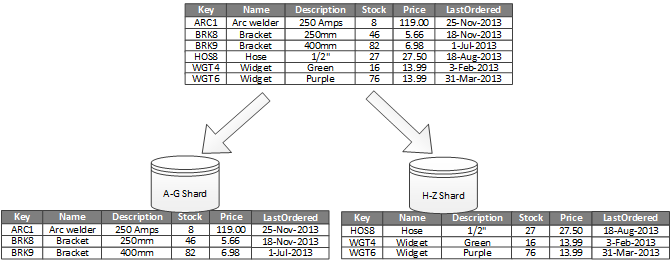
Each partition contains a portion of the data. A good strategy ensures each partition equally shares the system load. Each partition has the same schema and is also known as a shard.
An example of horizontal partitioning is arranging partitions by alphabetical order of keys. The most crucial aspect is deciding the range of the sharding key, as once the strategy is implemented and online, it is difficult to adjust.
This doesn’t mean that each partition should contain the same “amount” of data. For instance, if using an encyclopedia example, a publisher might design the books so that each volume has a similar thickness, arranging by alphabetical order to achieve balanced partitioning.
In database contexts, design might reflect real-world scenarios. Some shards might hold large amounts of data with low read/write frequency, while others hold smaller data with high read/write frequency.
Considerations:
- Ensure each shard does not exceed physical machine limits.
- Avoid creating “hotspots” that affect performance or reliability. For example, using customers’ first letters for key classification can cause uneven distribution due to linguistic habits. An alternative is hashing keys before distributing them into partitions.
Vertical Partitioning
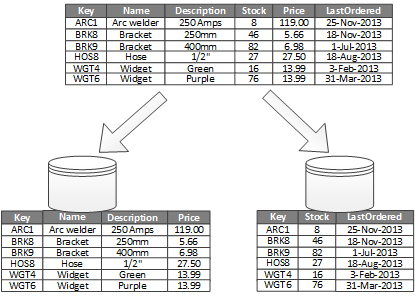
Each partition holds a subset of the original data. For example, split fields into frequently used and less frequently used parts, storing each in different partitions.
Vertical partitioning is commonly used to reduce I/O and lower the cost of frequently fetching data.
As illustrated in Fig2, one partition stores frequently accessed data like product names, descriptions, and prices. Another partition stores inventory and last order dates. This system frequently queries product-related data for app display, while inventory and order data are often shown together.
Additional benefits:
- Separating frequently changing items from infrequently changing ones. For example, product names, descriptions, and prices rarely change, whereas inventory counts and last purchase dates do. The less frequently changing data can be cached more easily.
- Sensitive data can be partitioned and protected with additional security controls.
- Vertical partitioning reduces the need for concurrent access. For instance, during an order, inventory and last purchase date change without locking the entire row. This strategy allows more rows per page in MSSQL compared to horizontal partitioning.
Functional Partitioning (Microsoft Article)
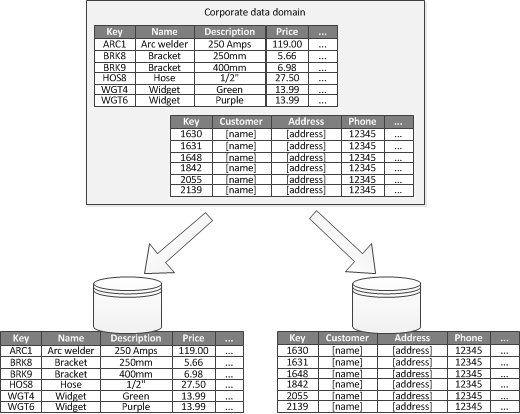
Functional partitioning divides data by usage. For example, in an e-commerce system, product inventory data might be in one partition, while invoices/receipts are in another.
If business logic boundaries are clear, functional partitioning can improve efficiency. A common scenario is separating read-write data from read-only data. In Fig3, inventory data and customer data are in different partitions.
Key or Hashed-based Sharding
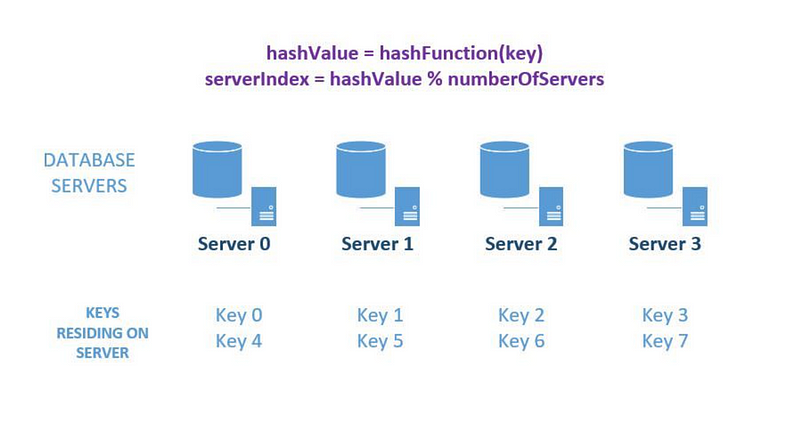
Assume you have four database servers, each request with an application id. Using hash and mod, you can distribute data across the four machines.
The main disadvantage of this method is that elastic load balancing (dynamically adding/removing database servers) becomes challenging and costly.
If you want to add six more machines, you must remap and migrate data, and adjust your hash function from mod 4 to mod 10.
There are ways to achieve seamless transitions, such as Consistent Hashing. Refer to the following resource: https://www.acodersjourney.com/system-design-interview-consistent-hashing/
Directory-based Sharding
Directory-based shard partitioning involves adding a lookup service in front of the partitions. The lookup service knows the current partition scheme and maintains a map record within the system.
Clients first query the lookup service to find out which shard contains the entity before performing the lookup.
Advantages:
- Solves elastic scaling issues without using consistent hashing. Assume the previous expansion scenario with four database servers and hashed-based partitioning. Now, add six more database servers without downtime.
Steps:
- The lookup service still uses mod 4 hash function.
- Determine how data should be divided under mod 10 conditions.
- Write a script to copy all data to the new six shards, without deleting data from the original four.
- Once copying is complete, change the hash function in the lookup service from mod 4 to mod 10.
- Purge or clean up data from the old four shards.
Considerations:
- During migration, users might still update data. Possible solutions include switching the system to read-only mode or temporarily storing data in another service, then moving it back after migration.
- Copying and cleaning up significantly impacts performance. Possible solutions are cloning and elastic load balancing, though both are costly.
Reference Articles
Partitioning Articles: https://www.acodersjourney.com/database-sharding/
Consistent Hashing: https://www.acodersjourney.com/system-design-interview-consistent-hashing/
Microsoft on Workload and Hotspot Mitigation: https://docs.microsoft.com/en-us/azure/architecture/best-practices/data-partitioning
By Marvin Lin on November 2, 2021.